Miten hallita lähdekoodia, jos kone kaatuu ja muutokset jäivät pois?
Tällöin siis voi olla epäselvää, että mikä versio siellä on, kun boottaat takaisin. Save:ahan on rämpätty yleensä milloin sattuu.
Kuitenkin, koodin kannalta, kuten vaikkapa proosankin kannalta, on oleellista, että lopputulos on ehyt. Olisi siten ikävää, jos avaat projektin aiempaan tilaan, mutta et ole varma, että onko aiempi tila esim. kaikilta osin selvä vai onko siihen jäänyt jotain tilapäisiä kokeiluja (kuten: // poista tama sitten joskus, // luokan XYZ kokeilu) tms.
Mikäli käytettäisiin jotain versionhallintaa, niin sinnehän yleensä lähetetään vain testattua koodia. Kuitenkin versionhallinnassa on sama ongelma, että jos kone kaatuu muutosten teon aikana, niin muutokset jäivät lisäämättä.
Pitäisikö koodata silleen, että suunnittelee etukäteen, että mitä aikoo tehdä, joten jos kone kaatuu teon aikana, niin aloittaa vaan alusta sen, mitä piti tehdä? Ja tällöin voi olettaa, että aiempi tallennuskohta on aina "ilman tätä muutosta"?
Toisaalta esim. myös monet avoimen lähdekoodin projektit ovat aika sotkuisia, joten ehkä se ei ole niin paha, jos siellä on jonkin verran turhaa koodia.
Tai ehkä jos kirjoittaisi uuden tai "prototyyppimäisen" koodin aina johonkin uuteen luokkaan tai funktioon, jolloin sitä voi testata modulaarisesti ilman, että tarvitsee sotkea jo siistejä ja funktionaalisia osia? Eikä esim. että kirjoittaa prototyyppikoodia vaikka suoraan main-osaan.
mavavilj kirjoitti:
Olisi siten ikävää, jos avaat projektin aiempaan tilaan, mutta et ole varma, että onko aiempi tila esim. kaikilta osin selvä vai onko siihen jäänyt jotain tilapäisiä kokeiluja tms.
Kirjoitat komentoriville esim. "git status" tai "git diff" niin tila selvenee.
jlaire kirjoitti:
(13.03.2024 15:10:59): ”– –” Kirjoitat komentoriville esim. "git status...
Nojoo siis, sitten varmaan kannattaa tehdä git:iä vaan riittävän usein, jotta muutokset ovat riittävän pieniä, jotta ne voi muistaa, jos ne pitää tehdä uudestaan.
Ongelma on, että kaikki lisäykset eivät välttämättä ole pieniä ollakseen funktionaalisia. Ja jos sinne lataa jotain, joka on vain osa jotain suurempaa, niin saadaan kysymäni ongelma eli miten tietää, että mikä se aiempi tila on, jos siellä on "puolivalmis jotain".
Jos se tekemäsi asia vaatii esim. 4 tuntia työtä ja kone kaatuu 2 tunnin kohdalla, niin pitäisi tietää ne 2 tunnin asiat tehdäkseen uudestaan. Ja niitä ei voi ladata git:iin, koska sitten siellä on "puolet jostain", ja pitää miettiä, että mitä siinä on tehty ja mitä puuttuu.
Joten luulen, että lisäykset pitäisi tehdä johonkin eri tiedostoon tms. joka tuodaan moduulina kokeiluvaiheessa tms. Jotta jo toimivaa ja siistiä ei sotketa kokeiluilla.
jlaire kirjoitti:
Kirjoitat komentoriville esim. "git status" tai "git diff" niin tila selvenee.
Aamen. Jos jostain syystä versionhallintajärjestelmä ei ole käsitteenä tuttu, on syytä tutustua välittömästi.
mavavilj kirjoitti:
Miten hallita lähdekoodia, jos kone kaatuu ja muutokset jäivät pois?
Tietokoneen kaatuminen on siinä määrin harvinaista nykyään, että harvoin pääsee isojen muutosten katoamista tapahtumaan. Jos olet edes tallentanut työn tai laittanut käyttöön automaattisen tallennuksen vaikka viiden minuutin välein, muutokset eivät katoa mihinkään, vaikka niitä ei olisi vielä viety versionhallintaan.
mavavilj kirjoitti:
Jos se tekemäsi asia vaatii esim. 4 tuntia työtä ja kone kaatuu 2 tunnin kohdalla, niin pitäisi tietää ne 2 tunnin asiat tehdäkseen uudestaan.
Se nyt vain on yksinkertaisesti huono työtapa. Automaattinen tallennus kannattaa olla käytössä, tai sitten kannattaa opetella muuten vain tallentamaan useammin.
mavavilj kirjoitti:
Mikäli käytettäisiin jotain versionhallintaa, niin sinnehän yleensä lähetetään vain testattua koodia.
Versionhallintaan ei ole pakko tallentaa vain valmista koodia, vaan nimenomaan Gitin tyyppisessä paikallisessa järjestelmässä voi tallentaa mitä tahansa väliaikaisia ja keskeneräisiä muutoksia. Jos vaikka kyllästyy tekemään tiettyä asiaa projektissa, voi tallentaa tämän keskeneräisenä muutoksena omaan haaraansa ja peruuttaa sitten siihen toimivaan versioon työstämään jotakin muuta osaa välillä.
Metabolix kirjoitti:
mavavilj kirjoitti:
Miten hallita lähdekoodia, jos kone kaatuu ja muutokset jäivät pois?
Tietokoneen kaatuminen on siinä määrin harvinaista nykyään, että harvoin pääsee isojen muutosten katoamista tapahtumaan. Jos olet edes tallentanut työn tai laittanut käyttöön automaattisen tallennuksen vaikka viiden minuutin välein, muutokset eivät katoa mihinkään, vaikka niitä ei olisi vielä viety versionhallintaan.
No minulla Debian 12 kaatuu n. joka toinen päivä, ja tämä on viikon vanha asennus. Ehkä Android Studio on buginen.
Metabolix kirjoitti:
Tietokoneen kaatuminen on siinä määrin harvinaista nykyään, että harvoin pääsee isojen muutosten katoamista tapahtumaan. Jos olet edes tallentanut työn tai laittanut käyttöön automaattisen tallennuksen vaikka viiden minuutin välein, muutokset eivät katoa mihinkään, vaikka niitä ei olisi vielä viety versionhallintaan.
Automaattinen tallennushan voi jättää sinne myös jonkin random-tilan, jossa on jotain raakileita tai kokeiluita tms. Ei se takaa, että siellä on aina ehyt ja toimiva versio.
mavavilj kirjoitti:
Ongelma on, että kaikki lisäykset eivät välttämättä ole pieniä ollakseen funktionaalisia.
Sekin on pitkälti taitokysymys. Isotkin muutokset on yleensä mahdollista paloitella toimiviksi paloiksi, jotka ovat kuitenkin jo sataprosenttisesti käytössä. Monissa projekteissa on vaatimuksena, että yksittäiset muutokset (commit, patch) eivät tuota kuollutta koodia, koska käyttämätöntä koodia ei voi testata esimerkiksi bisect-ominaisuudella. Esimerkiksi Winessä usein ensin tehdään funktiosta pelkkä tynkä (stub), jolloin funktiota on jo mahdollista kutsua, vaikka se ei tee mitään. Sitten aletaan lisätä funktion varsinaisia toiminnallisuuksia yksitellen.
Vaikka kehitysvaiheessa tekisi useampia osia samalla kertaa, myös muutokset on mahdollista refaktoroida järkevään muotoon. Githubissa tulee yllättävän usein vastaan, että joku on tosiaan tallentanut ja lähettänyt kaiken roskan. Eli ensin toteutetaan x sitten ups korjataan kirjoitusvirhe, sitten hups korjataan bugi. Tämän tyyppiset muutoshistoriat kannattaa kyllä ehdottomasti siivota kuntoon ennen muutosten lähettämistä internettiin.
mavavilj kirjoitti:
Automaattinen tallennushan voi jättää sinne myös jonkin random-tilan, jossa on jotain raakileita tai kokeiluita tms. Ei se takaa, että siellä on aina ehyt ja toimiva versio.
Ei varmaan kannata sinun kirjoittaa mitään koodia ikinä, koska koodi on kuitenkin välivaiheessa rikkinäinen ja toimimaton.
Automaattisessa tallennuksessa tiedät, että ei tarvitse tehdä uudestaan kahden tunnin työtä vaan viimeisen viiden minuutin työ. Toivottavasti kohdatessa aivot toimivat sen verran että tiedät, missä tiedostossa olit ja mitä asioita kirjoitit viimeisen viiden minuutin aikana.
Jos tekemäsi muutos on niin suuri, ettet pysty pysymään kartalla, mitä asioita olet muuttanut ja mitkä ovat kesken, selvästi olisi pitänyt suunnitella paremmin.
Metabolix kirjoitti:
Sekin on pitkälti taitokysymys. Isotkin muutokset on yleensä mahdollista paloitella toimiviksi paloiksi, jotka ovat kuitenkin jo sataprosenttisesti käytössä. Monissa projekteissa on vaatimuksena, että yksittäiset muutokset (commit, patch) eivät tuota kuollutta koodia, koska käyttämätöntä koodia ei voi testata esimerkiksi bisect-ominaisuudella. Esimerkiksi Winessä usein ensin tehdään funktiosta pelkkä tynkä (stub), jolloin funktiota on jo mahdollista kutsua, vaikka se ei tee mitään. Sitten aletaan lisätä funktion varsinaisia toiminnallisuuksia yksitellen.
Mistä löydän lisää tietoa siitä, miten kannattaa tehdä. Haluan kokeilla jotain stub-juttua tms. Ehkä tällainen järjestelmä on myös louhittava algoritmeilla, mikäli pitäisi monesta header:sta päätellä, että mitkä ovat toteutettuja ja valmiita ja mitkä jotain keskeneräisiä ja missä määrin.
Metabolix kirjoitti:
Automaattisessa tallennuksessa tiedät, että ei tarvitse tehdä uudestaan kahden tunnin työtä vaan viimeisen viiden minuutin työ. Toivottavasti kohdatessa aivot toimivat sen verran että tiedät, missä tiedostossa olit ja mitä asioita kirjoitit viimeisen viiden minuutin aikana.
Jos tekemäsi muutos on niin suuri, ettet pysty pysymään kartalla, mitä asioita olet muuttanut ja mitkä ovat kesken, selvästi olisi pitänyt suunnitella paremmin.
No noin käy esim., jos 5 minuutin aikana käsittelit useampaa tiedostoa, jotka eivät esim. liity toisiinsa läheisesti.
Tämmöisessä voisi teoriassa auttaa se, jos tallennuksen sijaan olisikin loki siitä, että missä olet ollut ja mitä tehnyt. Eli eräänlainen live-kopio.
Minun on vaikea uskoa, että vaikka viidessä minuutissa ehtisi tehdä niin monta niin riippumatonta asiaa, ettei niitä pystyisi muistamaan ja tarkistamaan. Jos nyt jossain työnkulussa nimenomaan joutuu tekemään näin ja kaatumisriski on iso, kannattaa varmaan panostaa siihen, että välitallentaa siinä hommassa jokaisen tiedoston jälkeen.
Jos kone tai ohjelma kaatuu niin usein, että tämä on ongelma ohjelmoinnin kannalta, on kyllä varmasti syytä ihan ensiksi korjata tämä asia ja vasta sitten jatkaa projektia. En nyt osaa sanoa, millä välineillä Androidille kannattaisi ohjelmoida, mutta sen verran suosittu alusta on kyseessä, että varmasti tähän on myös ohjelmia, jotka eivät kaadu koko ajan.
Puutteita on tapana kirjoittaa esimerkiksi kommentteihin, jotka alkavat TODO tai FIXME. Sillä tavalla ohjelmasta löytyy helposti keskeneräisiä kohtia.
Metabolix kirjoitti:
Minun on vaikea uskoa, että vaikka viidessä minuutissa ehtisi tehdä niin monta niin riippumatonta asiaa, ettei niitä pystyisi muistamaan ja tarkistamaan. Jos nyt jossain työnkulussa nimenomaan joutuu tekemään näin ja kaatumisriski on iso, kannattaa varmaan panostaa siihen, että välitallentaa siinä hommassa jokaisen tiedoston jälkeen.
No tuolloin taas jää puolinainen tekele siihen tallennukseen. Toimii, jos tietää, mikä koko homma on, mutta ei jos osan merkitys ei ole selvä. Tai jos ei muista, että mitä tiedostoja käsitteli tai missä järjestyksessä.
Metabolix kirjoitti:
Puutteita on tapana kirjoittaa esimerkiksi kommentteihin, jotka alkavat TODO tai FIXME. Sillä tavalla ohjelmasta löytyy helposti keskeneräisiä kohtia.
Jaa tuota voisi kokeilla. Sehän toteuttaa saman funktionaalisuuden kuin johonkin funktioon tai luokkaan eristäminen
Esimerkiksi tässä Android-projektissani teen:
session.open(sRuntime!!)
view.setSession(session)
// Testataan permissiondelegatea
val permission = ExamplePermissionDelegate()
session.permissionDelegate = permission
var permissions: Array<String> = arrayOf(Manifest.permission.RECORD_AUDIO)
requestPermissions(permissions, 1)
// /Testaan permissiondelegatea
session.loadUri("resource://android/assets/munsivujossain/index.html")Koska en ole erityisen kokenut Android:ssa, niin minulla on vaikeuksia muistaa, missä järjestyksessä ja missä kaikkialla permission:t pitää käsitellä. Tässä ne annetaan vain GeckoView:lle, mutta ne pitää olla vastaavasti manifestissa ja niille pitää olla myös käsittely onCreate:n luokan ylätasolla. Lisäksi niiden pyyntöihin GeckoView:n runtimestä pitää vastata. Joten jos lisään mainitun osan ja kone kaatuu, niin en teoriassa voi tietää, että toimiiko oikeudet jos tulen takaisin lisäämään vain nuo. Esimerkiksi, oliko ExamplePermissionDelegate jo valmis toteutus, kun sen nimikin on Example vielä.
Metabolix kirjoitti:
(13.03.2024 15:19:20): ”– –” Versionhallintaan ei ole pakko tallentaa...
Eli siis pitäisi työskennellä jotenki näin:
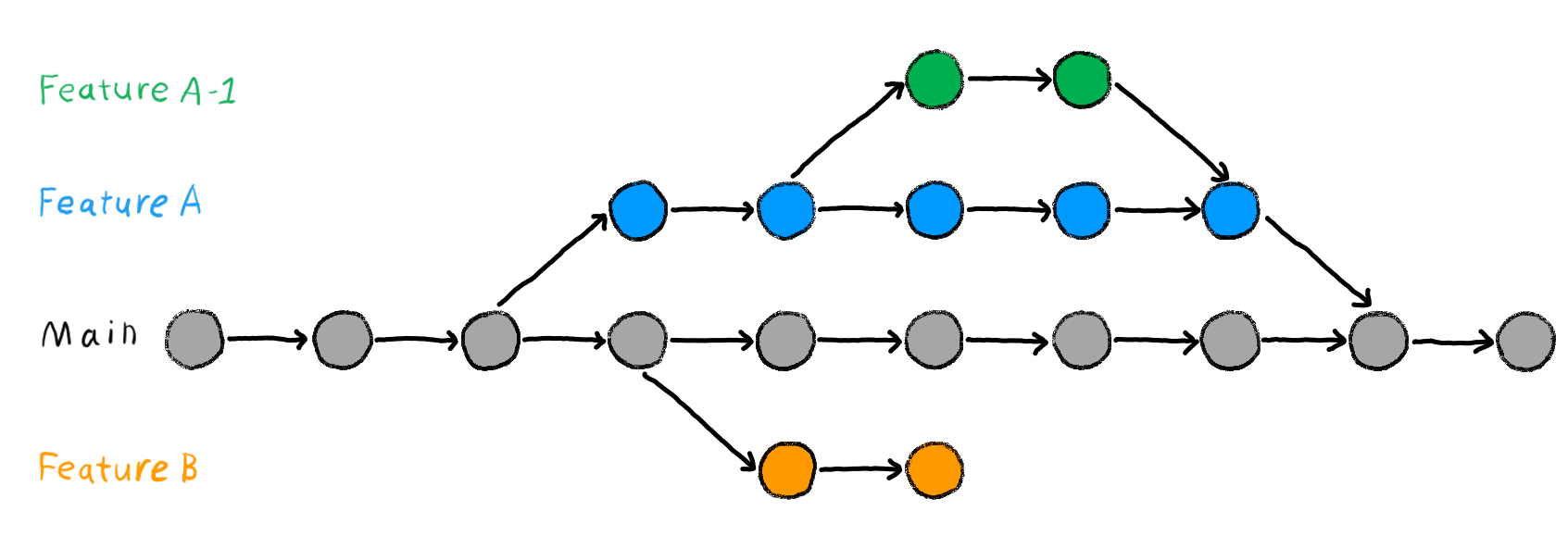
https://the-turing-way.netlify.app/_images/sub-branch.png
Eli lisättävät ominaisuudet voidaan tehdä valmiiksi eri brancheissa (otettu siis main:sta) ennen mergeemistä. Ja main:ssa voidaan edelleen tehdä muutoksia samanaikaisesti. Mergessä vaan tarkastetaan, että ei tule päällekkäisyyksiä? Eikä pitäisikään.
Eli pitäisi vaan muistaa, ettei feature-brancheissa saa koskea muihin kuin ko. featuren scopeihin. Ja main:ssa ei saa koskea featureihin.
Joo, versiohallintaan ihan mieluusti pieniä committeja, jolloin on muutenkin helpompi itsellekin nähdä, mitä siellä on muuttunut.
Niin siis ongelma ei ole versionhallinnassa, vaan siinä, että miten sitä kannattaa käyttää.
Esimerkiksi
mavavilj kirjoitti:
Eli pitäisi vaan muistaa, ettei feature-brancheissa saa koskea muihin kuin ko. featuren scopeihin. Ja main:ssa ei saa koskea featureihin.
Miten feature kannattaa enkapsuloida, jotta mergeröidessä sen ja main-branchin koodin välillä ei tosiasiallisesti ole riippuvuussuhteita?
Kirjoitetaan feature-branchiin feature ja testataan se feature-branchin main:ssa? Mutta mergetään main:iin vain feature, ja lisätään main-osa main-branchiin manuaalisesti?
Vai tarvitaanko vielä erikseen development-branch yms.?
No miten sitten development ja master mergeröidään siten, että ne eivät ylikirjoita toisiaan, eikä master:iin mene jotain roskaa?
Ei kai tuohon ole yhtä oikeaa tapaa. Olen kuullut suosituksesta, että gitiin voisi liittää uusia versioita kun testit läpäistään. Mutta mikäpä estää esimerkiksi tekemästä uuden haaran kokeiluille, jossa jokainen tiedoston tallennus menisi kokeiluhaaraan ja siitä sitten manuaalisesti yhdistettäisiin toimivat versiot päähaaraan? Näin jokainen tiedoston tallennus säilyisi muistissa.
mavavilj kirjoitti:
Miten feature kannattaa enkapsuloida, jotta mergeröidessä sen ja main-branchin koodin välillä ei tosiasiallisesti ole riippuvuussuhteita?
Kirjoitetaan feature-branchiin feature ja testataan se feature-branchin main:ssa? Mutta mergetään main:iin vain feature, ja lisätään main-osa main-branchiin manuaalisesti?
No siis. Tässä on se etu, että näin säilytetään eheys siinä, että main-branchissa on vain main:ia koskevia muutoksia, ja feature-branchissa vain kyseistä feature:a koskevia asioita. Jos siis feature:a kutsutaan main-osasta, sen muutoksen pitää olla main-branchin commit, eikä feature-branchin.
Android-esimerkissäni main-osa on MainActivity ja se, mitä tarvitaan, jotta se näyttää jonkin View:n yms.
Jos siis teen:
val permission = ExamplePermissionDelegate()
Niin tämä lisäys tulisi main-branchiin. Mutta tätä ennen ExamplePermissionDelegate tulisi olla täysin finalisoitu "ExamplePermissionDelegate"-branchissa. Tai ei välttämättä finalisoitu, mutta kutsun R.H.S.:n pitäisi koskea vain "ExamplePermissionDelegate"-branchissa olevaa koodia.
Toisaalta main-branchiin ei pitäisi tuottaa koodia, joka ei toimi täydellisesti.
Nyt pitäisi kuitenkin kysyä, että mihin kaikki permission:t tehdään? Osa niistä tulee manifestiin, joka sisältää main-osan asioita. Ja näitä tarvitaan, jotta voidaan varmistua myös siitä, että ExamplePermissionDelegate toimii oikein. Manifest:n tapauksessa pitäisi siis varmaan tuoda myös "sub-manifest".
On tietysti myös mahdollista, että itse Android SDK on huonosti modularisoitu. Tai ehkä kommentit ovat avain tähän. Eli sitten manifestiin muualta tuodut lisäykset tulisi kommentoida sellaisiksi.
Ihan kuin sinulla menisi sekaisin pääohjelma-main ja versionhallinnan main. Ei näillä ole mitään yhteyttä. Kyllä omaan haaraan tehdään kaikki tarpeelliset muutokset. Merge conflict ei ole ongelma vaan osa tavallista työnkulkua, tai vaihtoehtoisesti voi aina ennen mergeä tehdä rebasen niin, että konfliktit tulee ratkaistua jo ennen haaran yhdistämistä. Kukaan ei kiellä kehittämistä main-haarassa suoraan.
Tämä permission-asia voisi edetä vaikka seuraavasti (en tiedä Androidista, tämä on vain malli):
1. Ota selvää ja tarvittaessa tee erillinen testi, jotta tiedät varmasti, miten niitä oikeuksia saa.
2. Tee tynkä. Tässä esimerkissä ei ole parametreja, mutta jos tiedät, että niitä tarvitaan, voit lisätä ne jo nyt.
def hanki_oikeus():
# FIXME: stub
return False
# Jossain kohdassa, jossa oikeus tarvitaan:
if hanki_oikeus():
logger.debug("oikeus on")
return # FIXME: ei toteutettu!
else:
logger.info("ei oikeutta")3. Toteuta oikeuden hankinta.
4. Toteuta se koodi, jonka voi ajaa vain, kun oikeus on hankittu.
Metabolix kirjoitti:
(14.03.2024 16:05:09): Ihan kuin sinulla menisi sekaisin pääohjelma...
Branch-esimerkissä (kuvalinkit ylempänä) puhutaan featureista. Joten Android-ohjelmassa MainActivity ei ole feature, koska se on lähtökohtaisesti aina ohjelmissa.
Metabolix kirjoitti:
(14.03.2024 16:05:14): Tämä permission-asia voisi edetä vaikka...
Siis meinaat, että toisin kuin esimerkeissä sanotaan, niin git:n takia pitäisi tehdä erillinen funktio, joka palauttaa kaiken oikeuksiin liittyvän?
GeckoView ohjelmassa on kolme osaa.
-oikeus pitää määritellä manifestiin (erillinen .xml tiedosto)
-oikeutta pitää pyytää käyttäjältä runtimessä (esim. MainActivity.kt -tiedostossa)
-GeckoView:sta tulevat pyynnöt pitää "grantata" GeckoView:n API:lla overidetyissä funktioissa. Funktiot voi laittaa MainActivity.kt:seen.
Tässä on siis vain kaksi tiedostoa, mutta kolme kerrosta:
-AndroidManifest.xml
-MainActivity.kt (Android)
-MainActivity.kt (GeckoView)
mavavilj kirjoitti:
Branch-esimerkissä puhutaan featureista. Joten Android-ohjelmassa MainActivity ei ole feature, koska se on lähtökohtaisesti aina ohjelmissa.
Git-haarojen näkökulmasta feature voi olla vaikka se, että ohjelman tulostus ei ole enää "Hello world" vaan "Hei maailma". Älä sotke Gitin käyttöön turhia sääntöjä siitä, mitä ajattelet jonkin sanan tarkoittavan.
Mitä branch-esimerkkejä edes tarkoitat? Suosittelen lähdekritiikkiä, jonkun blogi tai opas tai esimerkki ei ole mikään velvoittava ohje gitin käyttöön. Ainakaan man git-branch ei sisällä feature-sanaa.
mavavilj kirjoitti:
Siis meinaat, että toisin kuin esimerkeissä sanotaan, niin git:n takia pitäisi tehdä erillinen funktio, joka palauttaa kaiken oikeuksiin liittyvän?
Kuten sanoin, en tiedä nimenomaan Androidin tai GeckoViewin ohjelmoinnista eikä itse asiassa edes kiinnosta. Käytin esimerkissä funktiota, jotta esimerkki mahtui pariin riviin, mutta tietenkin toteutat sen järkevästi ja sopivalla määrällä committeja. Esimerkin sisältö oli siinä, minkä tyyppiset vaiheet kehityksessä voisi suunnilleen olla, jotta tulee järkeviä rajattuja kokonaisuuksia eikä tarvitse hukata sitä 4 tunnin työtä kaatuvalla koneella.
Aiemmin valitit, että joudut käsittelemään kovin monia tiedostoja ja et pysty muistamaan 5 minuutin töitä. Nyt onkin vain 2 tiedostoa ja 3 muokattavaa kohtaa. Missä totuus?
Metabolix kirjoitti:
(14.03.2024 17:59:33): ”– –” Kuten sanoin, en tiedä nimenomaan Androidin tai...
No siis nämä liittyy toisiinsa. Oleellista on, että ei voi selvittää toisessa branchissa ollessaan, että mitä on tehty ja miten se liittyy toiseen branchiin, elleivät branchit ole tietoisesti erotettuja ja ellei niillä ole tunnettuja rajapintoja.
Jos menetät vaikka 2 tunninkin työn feature-branchissa, niin se ei kuitenkaan ole niin paha kuin sama main-branchissa, koska feature-branch on pienempi branch. Mutta on, jos sinun feature-branchit ja main-branchit tms. ovat riippuvaisia keskenään.
Metabolix kirjoitti:
(14.03.2024 17:45:53): ”– –” Git-haarojen näkökulmasta feature voi olla...
No tuo on minusta huono tapa määritellä feature. Minä määrittelisin featuren sellaiseksi, joka on toinen luokka tai vähintään toinen hyvin poikkeava funktio. Erityisesti, sen ei tulisi ottaa parametreina "main:sta" muuta kuin korkeintaan "this" eli kyseinen konteksti, jossa käyttöä tehdään. Mielummin ei sitäkään, vaan pelkästään dataa, eikä pass-by-referencenä.
Featuret esiintyvät ylempänä olevissa kuvalinkeissä.
Siis etkö saa tallentamaan sitä koodia kiintolevylle automaattisesti joka muutoksen jälkeen niin tiedot ei häviä vaikka kone kaatuisikin?
a karppinen kirjoitti:
Siis etkö saa tallentamaan sitä koodia kiintolevylle automaattisesti joka muutoksen jälkeen niin tiedot ei häviä vaikka kone kaatuisikin?
No joo, mutta riippuu siitä, että hakkaako tallennusta aina järkevän lisäyksen jälkeen, vai esim. puolivalmiidenkin asioiden jälkeen. Kuten sanottu, niin joskus toteutettava osa vaatii enemmän kuin "yhden muutoksen". Kuten Android-oikeudet esimerkissä. Jos tulee takaisin katsomaan jotain yhtä lisäystä, niin ei ole mahdollista tietää, että onko muuta tehty. Esim. jos välissä olisi viikko, että on kerennyt myös unohtamaan projektin.
mavavilj kirjoitti:
Metabolix kirjoitti:
(14.03.2024 17:45:53): ”– –” Git-haarojen näkökulmasta feature voi olla...
No tuo on minusta huono tapa määritellä feature.
Itse nyt juutuit tähän feature-sanaan ja johonkin oman Android-koodisi rakenteeseen. Mistä olet edes keksinyt, että Gitissä pitäisi olla jokin "feature"? Gitissä on haaroja, ja on käyttäjän oma asia, mihin näitä käyttää. Yleensä haara tähtää siihen, että jonkin asian saa tehtyä, olkoon asia sitten feature tai bugin korjaus tai ihan mikä tahansa. Usean haaran idea on se, että voi työstää useaa erillistä asiaa yksittäin tai tehdä mitä tahansa kokeiluja niin, ettei yhden asian keskeneräisyys tai bugi silti estä toisen asian kehittämistä.
mavavilj kirjoitti:
(14.03.2024 19:09:59): ”– –” No joo, mutta riippuu siitä, että hakkaako...
Etkö voi käynnistää koneen uudelleen ja jatkaa samalla tavalla kun jos kone ei olisi kaatunut, vai katkeaako ajatus enennkuin kone on käynnissä, en nyt tajua.
a karppinen kirjoitti:
mavavilj kirjoitti:
(14.03.2024 19:09:59): ”– –” No joo, mutta riippuu siitä, että hakkaako...
Etkö voi käynnistää koneen uudelleen ja jatkaa samalla tavalla kun jos kone ei olisi kaatunut, vai katkeaako ajatus enennkuin kone on käynnissä, en nyt tajua.
Niin oletuksella, että savettaa joka yhden muutoksen jälkeen.
Yhden muutoksen save-taktiikka ei ole kauhean kuvaava vaan siihen, jos jonkun muun pitää jälkeenpäin ymmärtää ohjelman rakenne. Silloin auttaisi enemmän, jos koodi on commitattu "itsenäisinä, kokonaisina moduuleina".
Eihän tuo nyt liity siihen mitenkään jos kone kaatuu, versionhallinta on sitten asia erikseen.
mavavilj kirjoitti:
Yhden muutoksen save-taktiikka ei ole kauhean kuvaava vaan siihen, jos jonkun muun pitää jälkeenpäin ymmärtää ohjelman rakenne. Silloin auttaisi enemmän, jos koodi on commitattu "itsenäisinä, kokonaisina moduuleina".
Myt menee taas tallentaminen ja Git commit sekaisin, aika huolestuttavaa. Vaikka tallentaisit joka kirjaimen jälkeen, tämä ei mitenkään vaikuta koodin ymmärtämiseen jälkikäteen. Tallentaminen vaikuttaa ihan vain siihen, missä tilassa tiedostot ovat, kun avaat ne seuraavan kerran.
Metabolix kirjoitti:
(14.03.2024 19:23:49): ”– –” Myt menee taas tallentaminen ja Git commit...
Eipäs, kun nehän ovat saman asian eri toteutustavat.
mavavilj kirjoitti:
Oleellista on, että ei voi selvittää toisessa branchissa ollessaan, että mitä on tehty ja miten se liittyy toiseen branchiin, elleivät branchit ole tietoisesti erotettuja ja ellei niillä ole tunnettuja rajapintoja.
Saman projektin haarat eivät ole "riippuvaisia keskenään" eikä niillä ole keskenään "rajapintoja". Ei ole tarkoitus, että saman asian yksi osa tehtäisiin yhdessä haarassa ja toinen toisessa haarassa (esim. funktio yhdessä haarassa ja funktiokutsu toisessa haarassa). Sehän olisi äärettömän typerää, kun koodia ei voisi edes testata kokonaisuutena. Yhden haaran pitää olla kokonainen toimiva kokonaisuus, joka yhdistetään päähaaraan sitten, kun se on järkevää eli kun kokonaisuus ei ole haittaavalla tavalla kesken.
Ja toistan vielä: millään haaralla ei ole mitään syvällistä erityistä arvoa tai periaatteellista rajoitusta, mitä osia koodista tietyssä haarassa voi muokata ja mitä ei. Päähaaran nimikin on täysin valinnainen: ennen master, nykyään main, ja itse voi vaihtaa sen nimeksi vaikka ällö-örvelö.
^ Mutta kuvalinkkien (https://the-turing-way.netlify.app/_images/sub-branch.png) esimerkeissä myös main etenee ja feature:t etenevät, mutta niitä ei mergeröidä jatkuvasti. Luin tämän siten, että featurea työstettäessä on mahdollista, että feature-branch ja main-branch eivät tosiasiallisesti toimisikaan yhdessä. Tai siis, lopussa feature:sta tulee main:n "current". Mutta mitä siinä välissä tapahtuu main:ssa? Onko main "non-building" silloin kun jokin feature on mergeemättä?
mavavilj kirjoitti:
Metabolix kirjoitti:
(14.03.2024 19:23:49): ”– –” Myt menee taas tallentaminen ja Git commit...
Eipäs, kun nehän ovat saman asian eri toteutustavat.
Nyt on kyllä outo väite.
Tallentaminen tallentaa tiedostoja esim. kovalevylle. Tiedostoista on levyllä yksi versio (viimeisin tallennus), ellei niistä erikseen luoda kopioita jollain tavalla. Tallentaminen ei muodosta minkäänlaista versionhallintaa.
Git commit tallentaa määrättyjen tiedostojen tietyn tilanteen erityisessä tiedostomuodossa niin, että myöhemmin on mahdollista vertailla tätä tilaa muihin tilanteisiin, palata aiempiin tilanteisiin jne.
Siis kaksi aivan eri asiaa.
Metabolix kirjoitti:
mavavilj kirjoitti:
Metabolix kirjoitti:
(14.03.2024 19:23:49): ”– –” Myt menee taas tallentaminen ja Git commit...
Eipäs, kun nehän ovat saman asian eri toteutustavat.
Tallentaminen ei muodosta minkäänlaista versionhallintaa.
Se on yhden version versionhallinta. n=1. + yksi haamuversio, joka on muistikuvasi tallennusta edeltävästä tilasta.
mavavilj kirjoitti:
^ Mutta kuvalinkkien esimerkeissä...
Miksi ajattelet, että nämä ihan satunnaiset jostain googlaamasi kuvalinkit (huom. et ole edes antanut lähteitä, missä yhteydessä kuvat on esitetty) antaisivat jotain todellista tietoa Gitin käyttötavoista tai suosituksista, mitä Gitillä pitää tai ei pidä tehdä?
Metabolix kirjoitti:
(14.03.2024 19:36:20): ”– –” Miksi ajattelet, että nämä ihan satunnaiset...
No ne näyttivät hyödyllisiltä esimerkeiltä. Anna paremmat?
mavavilj kirjoitti:
No ne näyttivät hyödyllisiltä esimerkeiltä. Anna paremmat?
Sinua selvästi rajoittaa sana ”feature”, niin korjaisin kuvat yksinkertaisesti vaihtamalla sanan ”feature” tilalle vaikka ”change”. Haara voi sisältää mitä tahansa, ei pidä jumiutua sanoihin.
Tavallinen tapa Gitin käyttöön on aloittaa muutoksille nimetty haara kuten vaikka wip-request-permissions-v1. Sitten vain koodaamaan kyseistä asiaa kuntoon. Tallenna usein. Tee committeja usein, mieluummin liian usein. Tee commit varsinkin aina, kun jokin pala tuntuu olevan valmis tai kun päätät muuttaa suunnitelmaa. Joskus kuitenkin käy niin, että uusi idea oli huono ja pitää palata takaisin, ja sitten harmittaa, jos välivaihe ei ole tallessa.
Jos suunnitelma osoittautuu huonoksi ja koodista tulee törkeää spagettia, voit tehdä uuden haaran, johon teet muutokset uudelleen paremmin. Kun pidät kokeelliset versiot tallessa, voit sieltä luntata vinkkejä.
Jos koodista tulee siedettävää, git log -p ja git rebase -i auttavat perkaamaan liian pienet commitit järkevämmäksi kokonaisuudeksi.
Vielä kolmas tapa historian siivoamiseen on käänteinen: Ensin viilaa uusi koodi oikein siistiksi ja tee tästä commit. Sitten poista koodista osia hallitusti ja tee poistoista committeja, kunnes päädyt takaisin alkutilanteeseen. Lopuksi käännä nämä muutokset takaperin (git revert) ja siivoa historiasta välivaiheet pois (git rebase -i).
mavavilj kirjoitti:
esimerkeissä myös main etenee ja feature:t etenevät, mutta niitä ei mergeröidä jatkuvasti. Luin tämän siten, että featurea työstettäessä on mahdollista, että feature-branch ja main-branch eivät tosiasiallisesti toimisikaan yhdessä. Tai siis, lopussa feature:sta tulee main:n "current". Mutta mitä siinä välissä tapahtuu main:ssa? Onko main "non-building" silloin kun jokin feature on mergeemättä?
Gitissä haara on lähinnä osoitin tiettyyn committiin. Mergen jälkeen mitään nimettyä toista haaraa ei tarvitse enää olla olemassa. Yksittäinen commit sisältää tiedon, mistä siihen on tultu, siis joko yhdestä suunnasta tai mergen kautta useasta suunnasta.
Jos lähdetään commitista A ja tehdään uusi haara B, niin jos myöhemmin commitin A kohdalla tehdään merge B, tästä ei jää mitään näkyvää haaraa puuhun, koska A sisältyy jo B:hen eli puun oksa kasvaa vain suorana. Haara ja merge jää näkyville historiaan vain, jos A:sta tehdään haarat B ja C ja myöhemmin yhdistetään nämä erisuuntaiset haarat B ja C toisiinsa.
Eli kun kaaviossa main etenee, niin joko siihen on mergetty jokin muu haara, jonka erillistä nimeä ei enää näy, tai sitten on tehty kehitystyötä suoraan mainiin, mikä on sekin täysin sallittua.
Missään tapauksessa tuo mainin eteneminen ei tarkoita, että siinä olisi jotain muihin haaroihin liittyvää rikkinäistä sisältöä.
mavavilj kirjoitti:
Pitäisikö koodata silleen, että suunnittelee etukäteen, että mitä aikoo tehdä, joten jos kone kaatuu teon aikana, niin aloittaa vaan alusta sen, mitä piti tehdä? Ja tällöin voi olettaa, että aiempi tallennuskohta on aina "ilman tätä muutosta"?
Kyllä pitäisi.
Itse käytän Windows alustalla edelleen kauan sitten ostamaani Realiable Softwaren Code Co-Op versionhallinta ohjelmaa. Git on tietysti parempi opetella mikäli osallistuu avoimen lähdekoodin projekteihin, mutta pelkästään omaan käyttööni tuo on mukavampi käyttää.
Eikö ole edullisempaa, jos tietty branchi tai sen nimi viittaisi tiettyyn modulaariseen osaan?
Vai ehkä tähän ei ole tarkoitus käyttää git:iä sinänsä, vaan ohjelmointikielen enkapsulointiominaisuuksia. Eli uusi modulaarinen feature on myös uusi tiedosto (esim. .kt).
Tässä on siis se idea, että koneen kaatuessa muutokset olivat vain lokaaleja (mieluiten yhtä tiedostoa tai jopa vain luokkaa tms. koskevia).
Metabolix kirjoitti:
Eli kun kaaviossa main etenee, niin joko siihen on mergetty jokin muu haara, jonka erillistä nimeä ei enää näy, tai sitten on tehty kehitystyötä suoraan mainiin, mikä on sekin täysin sallittua.
Eli tässä keskellä tapahtuu mitä?
Tämän:
mukaan siinä on siis tehty myös main:iin jotain.
Mergessä yhdistyy:
-feature -branch
-aiempaan branch:iin tehdyt muutokset
-se, mitä aiemmasta branch:sta on jäljellä
Mutta en ymmärrä, miksi tämmöinen branchaaminen on hyödyllisempää kuin se, että git-branchit vastaisivat suurin piirtein ohjelman kielen tiedostorakenteita (esim. .java tai .kt).
Erityisesti, en ole varma, miten git:ssä voi tutkia jälkeenpäin vain tietyn ominaisuuden läpikäymää kehitystä. Jos se on jossain vaiheessa mergeröity muuhun. Ja jos feature-branch ei ole kokonaisuus.
Minusta siis kannattaisi olla esim. se, että jokaista .java tai .kt tiedostoa ainakin vastaa yksi branchi.
mavavilj kirjoitti:
Mutta en ymmärrä, miksi tämmöinen branchaaminen on hyödyllisempää kuin se, että git-branchit vastaisivat suurin piirtein ohjelman kielen tiedostorakenteita (esim. .java tai .kt).
Koska varsinkin, kun kehittäjiä on useampia, niin on selkeämpää, että jokainen kehittäjä kehittää omaa branchiään, jolloin he saattavat muokata myös samoja tiedostoja.
Jos mitään versiointia ei ole, niin ei nämä kehittäjät tiedä omilla koneillaan, mitä muutoksia Jarkko on tehnyt autot.js -tiedostoon, jos Pena on muokannut samaa tiedostoa omalla koneellaan ja ylikirjoittanut tietämättään Jarkon muutokset.
Versiohallinta hoitaa mergen yhteydessä mahdolliset epäselvyydet ilmoittamalla niistä, jos muutosten yhdistäminen ei olekaan selkeää.
Branchit auttavat myös siinä tapauksessa, kun yksi kehittäjä kehittää useampaa toimintoa, mutta jää vaikkapa syystä X jumiin, ja joutuu palaamaan kehitettävän toiminnon pariin myöhemmin. Tällöin kesken jäänyt muutos ei haittaa, kun se elelee omassa haarassaan ja odottaa siellä yhdistämistä alkuperäiseen master -branchiin, kun joskus valmistuu.
mavavilj kirjoitti:
Erityisesti, en ole varma, miten git:ssä voi tutkia jälkeenpäin vain tietyn ominaisuuden läpikäymää kehitystä. Jos se on jossain vaiheessa mergeröity muuhun. Ja jos feature-branch ei ole kokonaisuus.
Riippuu siitä miten katsot tätä. Jos sulla on clienttinä jokin versiohallintasovellus, tai vaikka Bitbucketin/Githubin selaimella katsottava palvelu, niin näissä näkee ihan jokaisen commitin, mitä missäkin kohtaa on tehty.
Lebe80 kirjoitti:
mavavilj kirjoitti:
Erityisesti, en ole varma, miten git:ssä voi tutkia jälkeenpäin vain tietyn ominaisuuden läpikäymää kehitystä. Jos se on jossain vaiheessa mergeröity muuhun. Ja jos feature-branch ei ole kokonaisuus.
Riippuu siitä miten katsot tätä. Jos sulla on clienttinä jokin versiohallintasovellus, tai vaikka Bitbucketin/Githubin selaimella katsottava palvelu, niin näissä näkee ihan jokaisen commitin, mitä missäkin kohtaa on tehty.
Eli miten näkee vaikkapa kaikki MyPermissionHandler.kt:n commitit? Jos haluaa jälkeenpäin ymmärtää järjestyksen, jossa se on koottu?
Jos käytät Githubia, näet ne vaikkapa MyPermissionHandler.kt:n Blame -osiosta:
Tässä FastApin (oli ensimmäinen repo, mikä näkyi minulle etusivulla) README.md -tiedoston commitit
https://github.com/tiangolo/full-stack-fastapi-template/blame/master/README.md
Lebe80 kirjoitti:
Jos käytät Githubia, näet ne vaikkapa MyPermissionHandler.kt:n Blame -osiosta:
Tässä FastApin (oli ensimmäinen repo, mikä näkyi minulle etusivulla) README.md -tiedoston commitit
https://github.com/tiangolo/full-stack-fastapi-template/blame/master/README.md
No niin eli tämän perusteella branchien ei tarvitse vastata tiedostoja. Mutta commitien pitäisi olla järkeviä kokonaisuuksia.
Tuosta jatkokysymys, että miten nähdään commiteissa olevat riippuvuussuhteet? Eli jos on esim. lisätty tiedostoon jotain ja lisätty toisaalla kutsu tähän uuteen.
Branchit eivät vastaa tiedostoja, vaan muutosten "kokonaisuuksia", esim. meillä branchit nimetään "tukitikettien" perusteella.
Jos asiakas haluaa, että heidän järjestelmään tehdään muutos tai uusi ominaisuus, niin teemme tätä varten oman branchin, joka alkaa elään omaa elämäänsä siihen saakka, kunnes toiminto on valmis. Sitten se viedään takaisin testien kautta master-branchiin (johon on todennäköisesti tullut muista brancheistä muutoksia tänä aikana).
Sä näet tuolta Blame:sta kaikki kyseiseen tiedostoon tehdyt muutokset. Ne yhdistetyt branchit eivät jää mitenkään kiinni, vaan ne pitää aina yhdistää. Eli mitään riippuvuussuhteita ei ole.
Kaikki commitit näet (Githubissa) kustakin branchin commiteista:
https://github.com/tiangolo/full-stack-fastapi-template/commits/master/
Ja jokaista committia klikkaamalla, näet mitä kaikkia tiedostoja tässä commitissa on muokattu:
https://github.com/tiangolo/full-stack-fastapi-template/commit/
Pitääkö siten jokainen commit suunnitella sen kokoiseksi, että se lisää aina kokonaisen toimivan osan?
Tutkin siis tilannetta, jossa muokataankin aiemmin tehtyä ja pitää palata johonkin aiempaan toimivan tilaan. Ja myös tietää, mikä toimii. Tällöin olisi ikävä saada joku puolivalmis commit.
Lebe80 kirjoitti:
Eli mitään riippuvuussuhteita ei ole.
Miten niin? Branch sisältää aiemman branchin koodit, esim. masterin. Jos muokkaat master-osaa, niin master riippuu nyt branchistasi.
mavavilj kirjoitti:
Eli miten näkee vaikkapa kaikki MyPermissionHandler.kt:n commitit?
git log [-p] MyPermissionHandler.kt
mavavilj kirjoitti:
Tuosta jatkokysymys, että miten nähdään commiteissa olevat riippuvuussuhteet? Eli jos on esim. lisätty tiedostoon jotain ja lisätty toisaalla kutsu tähän uuteen.
Gitin näkökulmasta voisi sanoa, että commit on riippuvainen kaikista commiteista, jotka tulevat kyseisessä haarassa ennen sitä. Gitistä ei ole tarkoitus poistaa tietoja jälkikäteen (pois lukien haaran paikallinen siivous ennen pushia tai mergeä) eikä Git tulkitse koodia vaan ainoastaan säilyttää dataa, eli Gitin toiminnan kannalta ei ole tarvetta koneellisesti tietää mitään muuta "riippuvuussuhdetta".
Symbolin olemassaolon ja käytön välisen yhteyden voisi vielä koneellisesti tunnistaa, yleispätevästi riippuvuudet on kyllä todella vaikea havaita. Jos pidemmän funktion sisään lisätään uusi ehto tiettyä parametria koskien, ei ole välttämättä lainkaan selvää edes koodarille, onko kyseinen if-lause merkityksellinen jonkin tietyn funktiokutsun kohdalla.
No niin ja haluaisin tehdä versioiden hallintaa, jossa on mahdollista tietää ne funktionaaliset kokonaisuudet, ja esim. peruuttaa sellaiseen, poistaa kokonaisia toiminnallisuuksia, yms.
Mutta edelleen voi olla, että tämä pitäisikin tehdä lähdekoodin tasolla, eikä version hallinnassa.
Ehkä voi jopa sanoa, että jos asiaa pitää miettiä version hallinnassa, niin mahdollisesti koodi on huonosti modularisoitu.
mavavilj kirjoitti:
Mutta en ymmärrä
Monihaaraista kehitystä voi olla vaikea ymmärtää, jos ei kokeile. Tapoja on monia ja esimerkit rajoittuvat usein johonkin tiettyyn tapaan tai projektiin.
Jos projektissa on yksi "oikea versio" ja kaikki muu on kehitystä (tai jos oma rooli ei ole hallita niitä ison projektin erilaisia julkisia haaroja), kannattaa suhtautua omaan haaraan vain kehitystyön väliaikaisena työnimenä. Nimi ei välttämättä jää lainkaan historiaan, tai vaikka jäisi, se ei ole yleensä ensisijainen tapa hakea Gitistä tietoa.
Haaroista paremman käsityksen voi saada, jos tutustuu vaikka avoimen lähdekoodin projekteihin. Tyypillisesti jos haluaa jonkin muutoksen lähettää, siitä pitää tehdä oma haara, josta avataan sitten pyyntö (GitHubissa pull request, GitLabissa merge request). Jos koodi ja perustelut kelpaavat, projektin ylläpitäjä voi sitten yhdistää muutokset.
Katso esimerkiksi Winen merge requestit tai PHP:n pull requestit. Kun teet omaa projektia, olet tietysti samaan aikaan muutoksen ehdottaja ja hyväksyjä, mutta prosessi toimii samalla tavalla: yhteen haaraan tehdään yksi toimiva asia (looginen kokonaisuus, toiminto, korjaus), ja kun se on tarpeeksi hyvä, se liitetään päähaaraan.
Jos päähaaraan tulee välillä muita muutoksia oman kehitystyön aikana, kannattaa herkästi käyttää rebasea oman kehitysversion päivittämiseen. Monissa projekteissa ei hyväksytä lainkaan selkeästi vanhan version päälle rakennettuja haaroja. Liian vanhassa haarassa on riski, että jokin muutos on ristiriidassa uudempien kanssa, haaran yhdistäminen ei onnistu tai se ei toimikaan toivotusti. Vakavinta on, jos koodi näennäisesti on yhteensopivaa mutta toiminnallisesti ei olekaan, koska tällöin Git ei huomauta ongelmasta. Ajatellaan vaikka, että päähaarassa on muutettu koodin käännösasetuksia niin, että tekemäsi muutos ei käänny uusilla asetuksilla. Mergen jälkeen koodi olisi siis rikkinäistä.
Sopiva commitin koko riippuu tilanteesta ja projektin säännöistä. Aikanaan korjasin PHP:n base64_decode-funktion bugeja. Vikoja oli paljon, ja helppo ratkaisu olisi ollut vain tehdä kyseinen funktio kokonaan uudestaan (kuten kai ensin teinkin), mutta tämä ei ole usein toivottu lähestymistapa, koska tässä ei tule selväksi, miksi vanha versio toimi väärin ja miksi uusi versio toimisi sen paremmin. Tässä haarassa korjasin funktion bugit yksitellen, ja vaikka se voi tavallaan näyttää turhalta työltä, jokainen bugi ja muutos tuli selkeästi dokumentoiduksi ja perustelluksi.
mavavilj kirjoitti:
No niin ja haluaisin tehdä versioiden hallintaa, jossa on mahdollista tietää ne funktionaaliset kokonaisuudet, ja esim. peruuttaa sellaiseen, poistaa kokonaisia toiminnallisuuksia, yms.
Sitten pitää vain hakea Git-puusta merge commit (tai jos sellaista ei ole, pitää tunnistaa koko asiaan liittyvä peräkkäisten committien jono) ja kumota se git revertillä. Kyllähän tätä tapahtuu isoissakin projekteissa, että jokin ominaisuus osoittautuu bugiseksi ja se revertoidaan, kunnes tekijä tuottaa siitä paremman version.
Metabolix kirjoitti:
(15.03.2024 16:25:53): ”– –” Sitten pitää vain hakea Git-puusta merge commit...
Tämä sotkee myös main:n, mikäli koodi on tuollaisessa tilanteessa huonosti organisoitu. Ja haluaisin, että se olisi hyvin organisoitu.
Ehkä jos jokainen commit on sellainen, jonka jälkeen ei jää koskaan mitään "riekaleita", vaan pelkästään toimivia osia. Mutta tuollaisessa esimerkiksi se, että jokin commit onkin vain "oho vaihdoin kommenttia" sotkee sitä, että mitkä commitit ovat tärkeitä ja mitkä eivät.
Jos koodi on hyvin organisoitu tosin, niin ehkä commitien räpeltämisen sijaan voisikin vain poistaa ko. asiat tiedostoista itsestään ja tehdä uuden mergen?
Tässä nyt pohdin sitä, että olen nähnyt joitain commit-historioita, jotka ovat äärimmäisen vaikeasti tulkittavia, kun pitää ymmärtää, että mitä on tehty ja missä järjestyksissä tai millaisissa kokonaisuuksissa.
Haluaisin, että commit-historia olisi kuin päiväkirja, mutta commit-historiat eivät ole näyttäneet tällaiselta, vaan ne pomppivat vähän miten sattuu ja pitää olla expertti itse projektissa, jotta ymmärtää commit-historiasta jotain.
mavavilj kirjoitti:
Metabolix kirjoitti:
(15.03.2024 16:25:53): ”– –” Sitten pitää vain hakea Git-puusta merge commit...
Tämä sotkee myös main:n, mikäli koodi on tuollaisessa tilanteessa huonosti organisoitu.
Millä perusteella näin väität? Ei peruminen sotke enempää kuin alkuperäinen muutoskaan. Tietysti historiaan jää tästä jäljet, ja kannattaakin miettiä, voiko epävarmat ominaisuudet tuoda valinnaisiksi jollain käännös- tai suoritusvaiheen valitsimella, ettei tarvitse veivata edestakaisin. Hyvä modulaarisuus myös vähentää sotkua.
Mutta kyllä tietysti on niinkin, että täysin erilliset ominaisuudet kannattaa koodissa toteuttaa erilleen niin, että poistaminen onnistuu myös koodin tasolla.
mavavilj kirjoitti:
Haluaisin, että commit-historia olisi kuin päiväkirja, mutta commit-historiat eivät ole näyttäneet tällaiselta, vaan ne pomppivat vähän miten sattuu ja pitää olla expertti itse projektissa, jotta ymmärtää commit-historiasta jotain.
Korkean tason päiväkirjaksi ulkopuolisille voi pitää erillistä changelogia. Commitit ovat kehittäjille, ja niiden viesteissä on tapana selittää, mitä muutetaan ja minkä takia. Periaatteessa tageilla voisi halutessaan merkitä erityisiä kohtia historiassa, mutta ei tämä taida olla yleisesti käytössä minkään ominaisuuksien valmistumisen merkkaamiseen.
Ei siitä pääse mihinkään, että projektista pitää tietää paljon, jos aikoo sen kehitystä oikeasti ymmärtää. Voitko antaa jonkin konkreettisen esimerkin, mitä tietoa ei-eksperttinä tarvitsisi jonkin projektin commiteista kaivaa mutta ei kohtuudella löydy?
Ylipäänsä minusta olisi järkevää, että kokeilisit nyt käytännössä Gitin käyttöä johonkin projektiin ja jatkettaisiin keskustelua sitten, kun olet hankkinut vähän omaa kokemusta aiheesta. P.S. Googlaaminen ja lukeminen eivät ole kokemusta. Tee vaikka jokin perinteinen harjoitus kuten laskin, jossa eri laskutoimitukset ovat uusia haaroja ja testaat näiden mergeä ja reverttiä ja ristiriitojen ratkaisemista. Jos tert hyvän rakenteen koodille, voit tehdä myös useamman käyttöliittymän (GUI, TUI, HTTP) omina haaroina.
Metabolix kirjoitti:
mavavilj kirjoitti:
Metabolix kirjoitti:
(15.03.2024 16:25:53): ”– –” Sitten pitää vain hakea Git-puusta merge commit...
Tämä sotkee myös main:n, mikäli koodi on tuollaisessa tilanteessa huonosti organisoitu.
Millä perusteella näin väität? Ei peruminen sotke enempää kuin alkuperäinen muutoskaan. Tietysti historiaan jää tästä jäljet, ja kannattaakin miettiä, voiko epävarmat ominaisuudet tuoda valinnaisiksi jollain käännös- tai suoritusvaiheen valitsimella, ettei tarvitse veivata edestakaisin. Hyvä modulaarisuus myös vähentää sotkua.
Siis, koska on mahdollista, että peruutetaan osaan, jossa on uuden branchin aikana muutettu myös mainia, mutta vain osin, eikä loppuun asti.
Metabolix kirjoitti:
Ei siitä pääse mihinkään, että projektista pitää tietää paljon, jos aikoo sen kehitystä oikeasti ymmärtää. Voitko antaa jonkin konkreettisen esimerkin, mitä tietoa ei-eksperttinä tarvitsisi jonkin projektin commiteista kaivaa mutta ei kohtuudella löydy?
Ei kun olen ajatellut, että tämä on työkalujen ominaisuus. Koska olen nähnyt sekä hyviä projekteja että huonoja. Joten ajattelen, että tietämällä, mitä tehdä, voi tehdä siistin puun.
Joo lisäksi uskon, että kannattaa yrittää opetella past-masterseilta, ettei tarvitse hakata päätä samanlailla kuin he. Joku muu on aivan varmasti tähän päivään asti nähnyt kaikki ongelmat ja dokumentoinut ne.
Mutta minusta git vaikuttaa myös päällisin puolin siltä, että voi olla, että joku on kehittänyt myös version hallintaa.
Täällä puhutaan file-based architecture:sta:
https://www.perforce.com/blog/vcs/clearcase-vs-git
Branchit taitaa git:n mukaan olla tarkoitettu lähinnä vain isoloituihin lisäyksiin. Eli että uuden featuren voi toteuttaa kopiossa ilman, että tarttee pilata sitä, mikä toimi aiemmin. Näin ollen jokainen branch pitäisi olla aina toimivasta kopiosta.
Toisaalta tämä voi olla liian teoreettista, koska esim. Linux tai AOSP ovat aika rumia puita.
Hyvää tapaa voisi tutkia jossain GTK-pohjaisessa koodissa esim. Koska GTK tarjoaa oman objektimallinsa. Nopeasti ajateltuna commit-puun pitäisi heijastaa tätä objektimallia jotenkin.
Joo lopeta nyt se googlaus ja mene koodaamaan ja kokeilemaan.
Git-puu ei kuvasta koodin rakennetta vaan kehityksen aikajanaa. Haarat kertovat vain, että asiat on tehty samaan aikaan ja yhdistetty myöhemmin. Jos kaksi asiaa tehdään peräkkäin (ei rinnakkain), niistä ei muodostu näkyvää haaraa puuhun.
Haaroja voisi verrata ohjelmoinnin säikeisiin. Onko järkevää tehdä alussa oma säie joka funktiolle ja yrittää jotenkin viestiä näiden välillä? No ei ole. Pääohjelmassa tehdään pääasiat, ja säiettä voi käyttää, jos jotain pitää tehdä samaan aikaan taustalla häiritsemättä pääohjelmaa.
Metabolix kirjoitti:
(16.03.2024 06:07:47): Git-puu ei kuvasta koodin rakennetta vaan...
No niin no onko ohjelmointikielen omien enkapsulointitekniikoiden lisäksi jotain muita teknologioita?
Luultavasti näissä on kompromissi. Toisaalta kaikki halutaan manifest.xml:ään, mutta muutosten kytkösten näyttäminen olisi bloatia.
Metabolix kirjoitti:
Haaroja voisi verrata ohjelmoinnin säikeisiin. Onko järkevää tehdä alussa oma säie joka funktiolle ja yrittää jotenkin viestiä näiden välillä? No ei ole. Pääohjelmassa tehdään pääasiat, ja säiettä voi käyttää, jos jotain pitää tehdä samaan aikaan taustalla häiritsemättä pääohjelmaa.
Jotkin ohjelmat ovat siirtyneet multiprocess-enkapsulointiin ja IPC:hen.
mavavilj kirjoitti:
No niin no onko ohjelmointikielen omien enkapsulointitekniikoiden lisäksi jotain muita teknologioita?
En ymmärrä, mitä "ongelmaa" yrität ratkaista ja minkälaista tietoa nyt kaipaat. Siis mihin asiaan ei riitä koodin nykytila, dokumentaatio ja muutoshistoria (esim git log tai git blame)?
Metabolix kirjoitti:
(16.03.2024 09:34:34): ”– –” En ymmärrä, mitä "ongelmaa" yrität ratkaista...
Jos kokonaisuus koostuu useampaan tiedostoon tehdyistä muutoksista, niin jonkun työkalun pitäisi paljastaa, että lisäys tehtiin useampaan tiedostoon.
mavavilj kirjoitti:
Jos kokonaisuus koostuu useampaan tiedostoon tehdyistä muutoksista, niin jonkun työkalun pitäisi paljastaa, että lisäys tehtiin useampaan tiedostoon.
Tämä ei mitenkään vastannut kysymykseeni. Esimerkiksi mitä muutosta ja minkä takia yrittäisit tutkia tällä tavalla? Yksi muutos on yksi commit, ja sen tiedoista näkee, mitä tiedostoja se koskee. Useampia peräkkäisiä muutoksia voi tutkia git diffillä, jos jostain syystä ei halua katsoa committeja yksitellen.
No siis multiprocess-arkkitehtuurin etu on prosessien riippumattomuus. Jos branch onkin process, niin miten niiden riippumattomuus?
Branch ei ole process ja nyt olet taas täydellisen kujalla. Vertaukseni threadeihin oli nimenomaan vertaus tähän branchien luonteeseen ajan eikä sisällön kuvaajina eikä mikään ehdotus näiden kahden konseptin yhdistämisestä.
Sitä paitsi tuokin väitteesi ontuu pahasti. Monen prosessin arkkitehtuurissakaan prosessit eivät ole riippumattomia koodin ja rajapintojen suhteen, vaan ne ovat riippumattomia suoritusresurssien suhteen (ts. yhden kaatuminen tai tietoturvabugi ei aiheuta automaattisesti samaa ongelmaa toisessa). Jos prosessit ovat koodin osalta täysin riippumattomia, ei niiden kuulu olla Gitissä brancheja vaan (a) ihan vain erilliset osat lähdekoodissa, tai (b) erillisiä projekteja, joita kehitetään jollain tavalla synkronoidusti.
Siis eikö sinulla ole yhtäkään projektia, jonka kohdalla voisit nyt opetella Gitin käyttöä (joka on sinulle selkeästi täysin vierasta)? Ihan typerää keksiä uusia ongelmia, kun et ole opetellut edes alkeita.
Multiprocess-ohjelma luultavasti sisältäisi PermissionHandler -prosessin, joka yhdistää eri lähteiden oikeuskäsittelyt.
Aihe on jo aika vanha, joten et voi enää vastata siihen.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}